Introduction
For a project at work, we needed high quality SVG files for outlines of the individual US states. The requirements for these SVG files were that they needed to have a single fill color and they needed to be oriented in a straight fashion relative to the individual states themselves, rather than to a map of the entire country. So, for example, this image would not work for Pennsylvania because it is not straight:

However, that is how the state is oriented on a US map. Which is important to keep in mind for later. After extensive searching online, I couldn't manage to find a single collection of SVGs that suited our needs. Some of the individual states were available, but they were all formatted differently because they had been generated in different ways. I also found one or two SVG maps of the entire country which could be separated into states, but then the states wouldn't be oriented properly. Or at least, it would have been a big pain to transform the individual SVGs so that they would be. I had to figure something out.
The Accident
While hopelessly searching around Wikimedia for anything relevant to my task at hand, I kept stumbling upon images of US states that were filled with the colors of the LGBTQ flag, like this:

On the same web page as the flag, I found a link called "LGBT flag maps of United States". Of course, I followed it and found almost exactly what I had been searching for: an entire library of high-quality SVG files for all of the US states, oriented properly. There were only two problems:
- All of the states were the colors of the LGBTQ flag.
- There was no easy way to download all of the files at once.
Now, I could have simply visited each link one at a time and downloaded each file individually, but the computer scientist in me just wouldn't allow it. I had to write a script.
Beautiful Soup
Ah, Beautiful Soup. For any of you that aren't already familiar with this Python library, it functions in conjunction with urllib2 (or more recently in Python 3, urllib.request) to allow you to easily parse through HTML documents for specific elements and specific attributes, classes, ids, etc. The ease with which you can access specific elements in HTML docs is on par with that of jQuery's ability to grab DOM elements on web pages.
Beautiful Soup also makes your HTML docs more readable with the prettify() function. Many times the HTML returned from a GET request will be difficult to read, but Beautiful Soup spaces HTML tags properly for you, making it really easy to scan through quickly to find what you need.
Let's Get Pretty
In order to solve my first problem, I needed a script that could do a GET request at the URLs of every individual SVG file and save the responses so I could edit them afterwards. It would have been nice if the solution were as simple as visiting the same root URL + "state_name.svg" appended to the end. Then I could just loop through an array of states, appending the name to the end of the URL during each iteration and then sending out the request. Unfortunately in the web world, nothing is ever that simple.
Each state's file had the same base URL, plus a seemingly random letter followed by a forward slash, that same letter plus a seemingly random number, another forward slash, and then the state's name. For example, the link to the Pennsylvania SVG file was
https://upload.wikimedia.org/wikipedia/commons/e/ef/LGBT_flag_map_of_Pennsylvania.svgand the link to Idaho SVG file was
https://upload.wikimedia.org/wikipedia/commons/b/b7/LGBT_flag_map_of_Idaho.svgI'm sure there is some method to this system, but for the life of me I couldn't figure it out, and I knew that I didn't need to. Wikimedia had no collection of download links for all of the files, but it did have a page that listed all of the links to the pages that contained those download links I needed.
I could write a script that gets the HTML from that page, grabs all of the links to the individual state pages, visits each of those pages one at a time, grabs the link to the download for the file, and then grabs the file and writes it to my local machine. Phew. That's a lot, but with Beautiful Soup it's actually simple. First thing was first, I needed to grab all of the links, so I printed out the prettified HTML response to see how I could identify these guys and get them from the HTML. Here's the code:
import urllib.request
import fileinput
import sys
from bs4 import BeautifulSoup
url = 'https://commons.wikimedia.org/wiki/Category:LGBT_flag_maps_of_United_States'
response = urllib.request.urlopen(url)
soup = BeautifulSoup(response.read(), 'html.parser')
for link in soup.find_all('a'):
url = link.get('href')This code uses urllib.request to get the HTML from the flag maps web page, and then uses BeautifulSoup to find all of the <a> tags. Now, there were many more<a>tags in this collection than I actually needed because of random links that were placed all over the wiki page, so I had to somehow distinguish between the links that led to the US state pages and the others. After a quick print(soup.prettify()), I was able to see that every single link that I needed contained the string "flag_map_of". A quick modification to the code and I had all the links I needed!
Next, I had to visit all of those links, grab the link to the download, and then do a GET request to those URLs. I did this basically by repeating the process I used to get the links to the individual pages in the first place, so I'll just skip the explanation and show you the code:
for link in soup.find_all('a'):
url = link.get('href')
if url != None:
if 'flag_map_of' in url and 'United_States' not in url:
url = 'https://commons.wikimedia.org' + url
response = urllib.request.urlopen(url)
soup2 = BeautifulSoup(response.read(), 'html.parser')
link = soup2.find_all('a', { 'class' : 'internal' })
url = link[0].get('href')
sections = url.split('_')
filename = sections[len(sections) - 2] + '_' + sections[len(sections) - 1]
if 'of_' in filename:
filename = sections[len(sections) - 1]
with urllib.request.urlopen(url) as response, open(filename, 'w') as out_file:
svg = response.read().decode('utf-8')
out_file.write(svg)
out_file.close()Straightening Things Out
Okay, so I solved problem number one by using Beautiful Soup to grab all of my files for me, but I still had to solve problem number two. Currently, all of my SVG files were the colors of the LGBTQ flag, so I needed a script to edit them. I thought that this might be as simple as scanning the files for fill colors and editing them appropriately, but alas, yet again, nothing is that simple in the web world.
In the same for-loop that created my SVG files for me, I was going to edit them as well. In hindsight, I probably should have broken this up into two separate scripts, but it doesn't matter much now. For each SVG file, I scanned the XML and replaced all instances of LGBTQ fill colors with a solid-gray fill color. The code for this is below:
for line in fileinput.input(filename, inplace=True):
strip = line.strip()
if strip == 'style="fill:#e40303"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
)
elif strip == 'style="fill:#ff8c00"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
)
elif strip == 'style="fill:#ffed00"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
)
elif strip == 'style="fill:#008026"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
)
elif strip == 'style="fill:#004dff"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
)
elif strip == 'style="fill:#750787"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
)
else:
sys.stdout.write(line)Pretty straightforward. If a line of the file contains a bad fill color, it replaces it and writes the new line to the file. Otherwise, it just writes the original line. At first I thought that this worked. When the SVG was rendered as an image above a certain size, it looked perfect, but once the size was decreased to something like a width of 500px, lines began to show up in the image, revealing the background behind the SVG, like so:
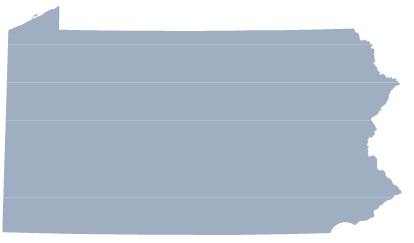
These images needed to be fully responsive, so that was no good. To fix this problem, I first tried changing the stroke fill and thickness of the SVG paths. Below each new fill-color line, I added two more lines of code, like so:
if strip == 'style="fill:#e40303"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
'\t stroke="#9FAEC0"\n'
'\t stroke-width="10"\n'
)To my dismay, this didn't quite work, either. Once the image was made small enough, the white lines were still clearly visible. I couldn't increase the thickness of the stroke much more or the images would become odd-looking, so I had to try something else.
The solution that ended up working was a transform on each of the SVG paths to move them closer to one another. The bottom section of the state would stay put, the section above that would move down, the section above that would move down even more, and so on. After some trial and error, I was able to get some pretty good-looking SVGs by translating the SVG paths down in multiples of 25px. The final code to edit each file looked like this:
for line in fileinput.input(filename, inplace=True):
strip = line.strip()
if strip == 'style="fill:#e40303"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
'\t stroke="#9FAEC0"\n'
'\t stroke-width="10"\n'
'\t transform="translate(0, 125)"\n'
)
elif strip == 'style="fill:#ff8c00"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
'\t stroke="#9FAEC0"\n'
'\t stroke-width="10"\n'
'\t transform="translate(0, 100)"\n'
)
elif strip == 'style="fill:#ffed00"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
'\t stroke="#9FAEC0"\n'
'\t stroke-width="10"\n'
'\t transform="translate(0, 75)"\n'
)
elif strip == 'style="fill:#008026"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
'\t stroke="#9FAEC0"\n'
'\t stroke-width="10"\n'
'\t transform="translate(0, 50)"\n'
)
elif strip == 'style="fill:#004dff"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
'\t stroke="#9FAEC0"\n'
'\t stroke-width="10"\n'
'\t transform="translate(0, 25)"\n'
)
elif strip == 'style="fill:#750787"':
sys.stdout.write(
'\t style="fill:#9FAEC0"\n'
'\t stroke="#9FAEC0"\n'
'\t stroke-width="10"\n'
)
else:
sys.stdout.write(line)Conclusion
Other than a couple of anomalies which I had to manually fix (Kansas.svg didn't have the keywords in each line I was searching for and New_York.svg didn't need the translations for some reason), the SVGs turned out great. The entire library of US State SVGs is available on my Github profile located here. Feel free to use them for any of your projects! Also, feel free to e-mail me or comment below if you have any questions at all and I will try to answer them as quickly as possible.